Bug prioritisation
One of the most challenging balancing acts in Product Management is maintaining product quality while still being focused on delivering value. The question of "what do we do about this bug?" can create tension in outcome focussed teams. If you are working towards driving a particular metric or goal, should bug fixes be prioritised over achieving that goal?
Feeling this tension within teams I have worked with, I explored this question with fellow PMs in the Continuous Discovery Habits community, where approaches varied widely. One team dedicates two weeks at the end of each feature sprint specifically for bugs, snags and developer-prioritised work that relate to the sprint. They said that this way developers knew that they would be able to address things in the code that they felt strongly about, whilst maintaining focus on the sprint goal. A tech-lead informed me of an alternative stance, having a "zero bugs backlog" policy; either fix it now or delete the ticket. I also recall when I used to work with the MakeCode team at micro:bit, bugs would be given Priority tags; P0 being a critical fix to P2 which often ended up as "won't fix". These were triaged weekly, but not always addressed until the yearly main release.
These conversations inspired me to develop a clearer framework with my team. As with most things, we tried to do this visually in Miro to co-create a process. What emerged was a severity-priority matrix that has transformed how we handle bugs and "anomalies" (things we aren't yet sure are bugs).
The severity x priority bug prioritisation matrix
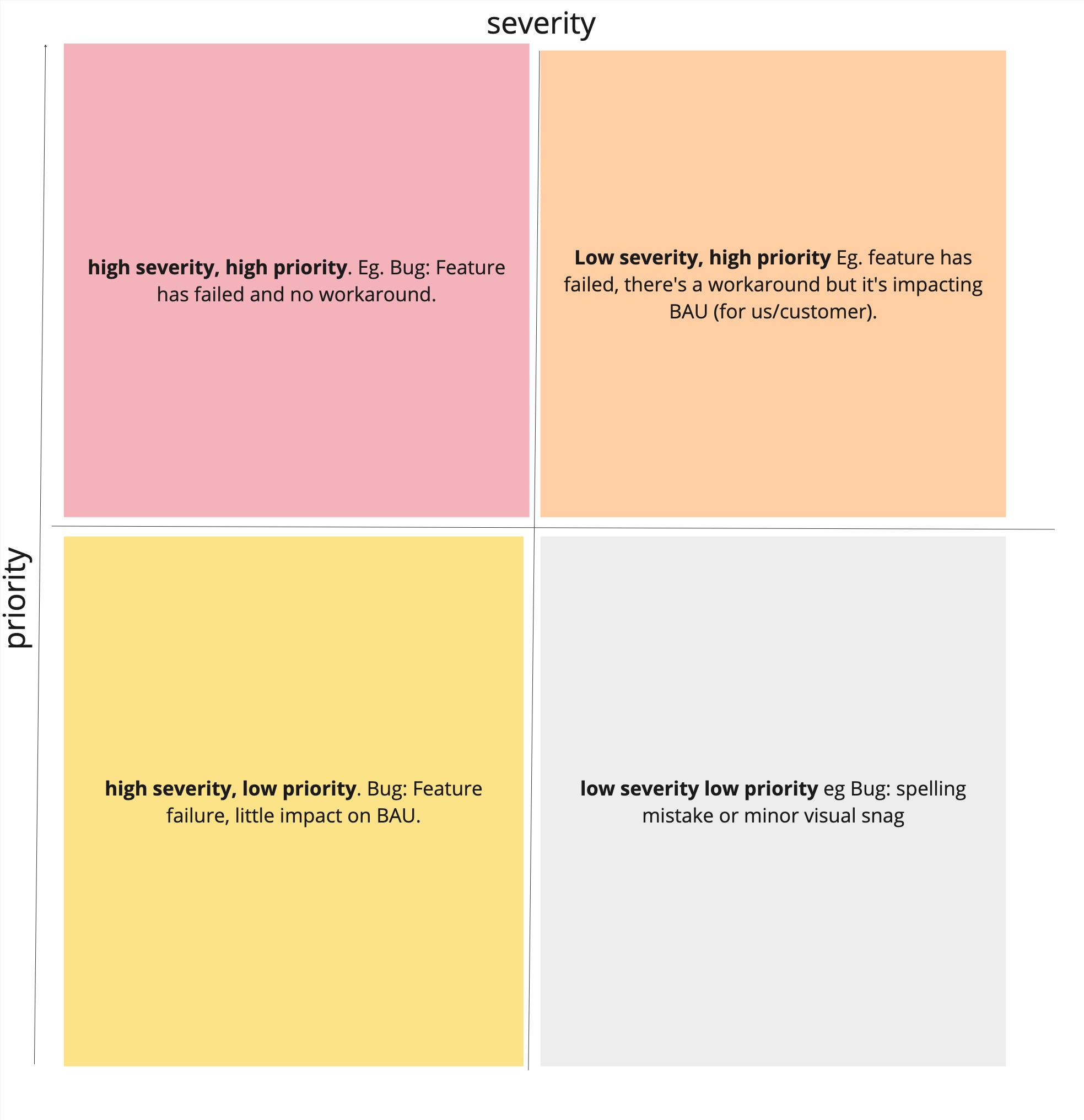
The matrix plots two critical dimensions:
- Severity: The impact on users and business functions
- Priority: The urgency for addressing the issue
This creates four quadrants that guide our response to different types of issues. Issues can be mapped as either high or low across the dimensions.
High Severity, High Priority eg. Feature failures with no workaround
Low Severity, High Priority eg. Feature has failed, there is a workaround but it's impacting BAU for the customer or the team
High Severity, Low Priority eg. Feature failure with little impact on BAU and
Low Severity, Low Priority eg. Spelling mistake or minor visual snag
Beyond assessing bugs: Prioritising the work
These quadrants gave us a space in which to discuss where we would how to assess or triage the issue, but I soon found that the team were still asking questions about the priority. Should something interrupt ongoing work? Should it be the next thing in the queue? We decided to visualise these decisions on our matrix. For example, in the case of feature failure we felt this should jump to the top of the queue and interrupt ongoing work.
Beyond assessing bugs: The "Anomaly" Category
Another part of the team's weekly rituals is to review error logs. On one occasion we saw that we had over 250k errors in the last week relating to one feature. One of our key innovations was adding the concept of "anomalies"—issues where we're not even certain if there's a bug or what's causing unusual behavior. For these, we created a time-boxed investigation process that helps us understand the root cause and potential impact before committing resources.
By evolving this process over time we ended up with a map that articulated priorities, examples and actions to take.

High Severity, High Priority
Examples:
- Feature failures with no workaround
- Critical errors (like our case where 250k errors were reported weekly for a critical feature)
Action: Straight to the top of the queue, interrupting ongoing work and fix
Low Severity, High Priority
Examples
- Features that have failed but there's a workaround. Recently shipped feature warranty sits here too
- Unusual activity like lots of versions in an activity feed but they are not articles, we don't know why this is happening
Action
Strait to the top of the queue after completing WIP. Time-box the activity if it's an anomaly
High Severity, Low Priority
Examples
- Feature failures with little impact on BAU for the customer or for us
- System errors impacting low-usage functions like group management
Action
Ask how long we can live with? Can we let it resurface? If so, delete the sticky/issue
Low Severity, Low Priority
Examples
- Spelling mistakes
- Visual inconsistencies
- Edge cases with unclear impacts
Action
Add to a 'pick-up' box or delete
Evolution of Our Approach
The matrix wasn't a static creation. We enriched it by:
- Adding historical examples to each quadrant
- Creating specific process notes for each category
- Documenting clear response procedures (e.g., "straight to the top of the queue, interrupt ongoing work")
Reflections and Challenges
The lower quadrants were hard to quantify or qualify for priorities. When you focus on a question of "is this the most important thing to be working on?", it's hard to prioritise anything that ranks 3rd or 4th. That being said, minor visual snags such as those in low severity x low priority can often be little things that make the UX feel unloved, so it's important to deal with them. How you do that is open to interpretation; having a snags list or pick-up bucket can help, but you need to make time to pick up that work against all the other competing priorities.
Finding A Balance
What I've learned through this process is that bug prioritisation isn't one-size-fits-all.
The key benefit of our matrix approach isn't necessarily the exact categorisations, but the shared understanding it creates within the team. When everyone knows how we evaluate and respond to different types of issues, decisions become faster and less contentious.